AI Risks Don't Wait for Committees
How operational risk management turns AI governance from policy into action


In a previous piece, Point-of-View: AI Governance is Broken, we described a three-pillar approach to AI governance – the policies, principles, and accountability structures that define an organization’s intent. Yet across the enterprise, a familiar pattern persists: policies get written; principles are endorsed; and committees are formed. And when an AI system degrades quietly or creates unintended downstream consequences, leaders discover that governance stopped at the point of good intentions.
Imagine a demand-forecast model whose error rate drifts after a quiet upstream data change; revenue leakage accumulates for weeks before anyone can prove where the shift began. The postmortem is not about ‘AI ethics’ in the abstract, but rather, it is about telemetry, ownership, and escalation. The reality is that AI risk doesn’t live in policy documents. Instead, risk emerges through day-to-day decisions, unexpected system behavior, and operational tradeoffs, the very areas where AI risk management matters most.
In a mature AI program, governance sets direction and intent, while operational risk management determines how those intentions translate into real outcomes. Because risk manifests unevenly, not all AI systems require the same level of operational rigor. Controls must scale with business impact, ensuring speed for low-risk experimentation while demanding stronger discipline for systems that influence customers, critical decisions, or regulated outcomes.
Governance Sets the “What” and the “Why”
An enterprise’s governance framework establishes the organization’s intent for AI use. This framework answers foundational questions such as:
What risks will we tolerate, and in which contexts?
What ethical and legal boundaries constrain us?
Which use cases advance strategic priorities?
Who decides, and who is accountable?
For governance to be effective, accountability must sit with the business. Every AI system with meaningful impact on customers, clinical or financial outcomes, regulatory posture, or brand trust should have a named business executive as the accountable risk owner – someone with authority over the system’s real-world consequences. Technology and risk teams enable controls and provide independent challenges, but they do not own the outcomes.
In our three-pillar governance framework, these decisions are shaped through distributed accountability:
First-line employees who surface ground truth from real AI use
A cross-functional oversight body that aligns risk with enterprise priorities
An independent audit function empowered to challenge assumptions
Together, these pillars define decision rights, escalation paths, and acceptable risk.
Operational Risk Management: the “How” and the “Who”
Operational AI risk management is where governance intent turns into daily practice. This framework, well-implemented, is responsible for identifying and mitigating risk as systems evolve; implementing controls and guardrails; monitoring performance for drift and anomalies; and responding to incidents with containment and learning.
This layer is where accountability becomes tangible. When something goes wrong, operational risk management determines whether the organization detects the issue early, responds effectively, and learns from the event. Without this layer, governance remains theoretical.
A Complementary View of AI Risk
AI risk is often described through categorical frameworks, such as the NIST AI Risk Management Framework, which organize risk into areas like data integrity, model validation, security, fairness, and monitoring. These taxonomies are useful, because they help organizations enumerate the kinds of risks that may exist across the AI lifecycle.
Our framework does not dispute this view, but it shifts the axis of organization. In addition to classifying risk by type, we organize it by how risk is managed inside an enterprise: lifecycle controls, runtime monitoring, data operations, human oversight, and operational resilience. These domains map directly to ownership boundaries, escalation paths, and day-to-day decision-making.
This distinction, moving from abstract categories to operating domains, matters for two reasons. First, it enables proportionate rigor. Not every AI application requires the same level of oversight; an internal meeting summarization tool does not demand the same lifecycle controls as a customer-facing diagnostic system. By organizing risk into operational domains, leadership can establish “fast-track” pathways for low-stakes experimentation while applying deep technical discipline on high-impact systems. This approach prevents governance from becoming a uniform bottleneck, instead ensuring that oversight resources are allocated where they most effectively protect the enterprise.
Second, this approach clarifies accountability. Risk categories describe what can go wrong. Operating domains determine who is accountable, when signals surface, and how governance adapts based on real system behavior. In practice, AI failures rarely occur because a risk category was misunderstood. Failures occur because signals were missed, ownership was unclear, or feedback never reached someone empowered to act.
This framing does not create a new governance program. It embeds AI risk into the organization’s existing risk machinery: enterprise risk management, security incident response, compliance, audit, and vendor oversight. The question is not whether AI controls exist, but whether AI failures move through the same escalation, accountability, and resolution pathways as other material risks.
When AI governance is treated as an overlay, signals fragment and accountability is diffused. When it is embedded into the enterprise operating model, risk becomes visible, escalation becomes routine, and learning becomes systematic. This makes AI governance executable in practice: complementing established standards while focusing attention on the mechanisms that turn policy into action and principles into sustained performance.
Five Domains of Operational AI Risk Management
Effective operational AI risk management spans five interconnected domains. These domains function as a flow: “Model Lifecycle Controls” and “Data Operations Risk” establish the baseline for a system before deployment; “Runtime Monitoring and Response” and “Human-in-the-Loop Integration” manage performance and intervention during active use; and “Operational Resilience” ensures business continuity during system failures. Once the lessons learned are reintegrated back into governance controls, this flow becomes a closed loop. The domains apply across all AI systems, but the rigor of controls within each should scale with the system’s impact and risk.
1. Model Lifecycle Controls
AI risk begins well before deployment, and is shaped by how a system is built, approved, changed, and ultimately retired. Effective lifecycle controls focus on four areas:
Pre-deployment validation for accuracy, bias, and robustness, including adversarial inputs and edge cases that reveal failure modes.
Version control and model registries that establish provenance. Without lineage, organizations cannot reproduce results, diagnose failures, or assign accountability.
Formal change management for retraining, prompt updates, and configuration changes. Even minor modifications can produce behavioral shifts that bypass review.
Defined decommissioning procedures to prevent “zombie models” from persisting in forgotten pipelines, creating audit and security gaps.
A common failure mode is that high-visibility systems receive scrutiny, while lower-profile models evolve quietly through hotfixes or retraining. Visibility is not the same as impact, and lifecycle controls should scale with a system’s potential impact, not its popularity.
2. Data Operations Risk
AI systems inherit the risks of the data that feeds them, and such upstream data can reshape system behavior over time. Effective data risk management focuses on five areas:
Data quality checks and lineage tracking to trace failures back to their source, whether a corrupted sensor feed, stale reference table, or undocumented preprocessing change.
Privacy-preserving techniques, such as differential privacy or federated learning, which introduce design trade-offs and require early alignment among technical, legal, and business stakeholders.
Access controls aligned with data sensitivity and use, applying least-privilege principles rather than broad permissions granted for convenience.
Protection against data contamination and poisoning, whether accidental, such as labeling errors or tainted scraped data, or intentional, through adversarial injection designed to manipulate model behavior.
Controls on feedback loops in generative systems, where ungoverned user input can reinforce errors, bias, or unsafe patterns, causing models to degrade quietly while appearing stable.
3. Runtime Monitoring and Response
The most consequential AI failures emerge after deployment, making runtime behavior the critical control point. Effective monitoring must reveal when systems are changing or degrading in production, including:
Performance degradation from data drift or concept drift, where shifting inputs or altered underlying relationships silently erode accuracy until failures surface through downstream impact or user complaints.
Anomalous or unsafe outputs, requiring detection mechanisms that distinguish legitimate edge cases from hallucinations, biased recommendations, or policy-violating responses.
In-line guardrail enforcement, where problematic outputs are intercepted before reaching users or downstream systems, balancing latency and decision accuracy.
Monitoring alone is insufficient. Alerts require named owners, defined escalation paths, and time-bound expectations for containment and resolution. If no one is accountable for acting on a signal, control does not exist.
4. Human-in-the-Loop Integration
“Human oversight” is often invoked as a safeguard, without specifying where judgment, override, or escalation actually occurs. Effective human-in-the-loop design requires explicit structure, including:
Clear criteria for mandatory human review, replacing vague guidance with consistent, actionable thresholds.
Auditable override mechanisms that capture reviewer identity, reasoning, and outcomes.
Defined escalation triggers for ambiguous or high-stakes decisions, ensuring that routine cases are handled efficiently while novel or sensitive situations reach appropriately senior or multidisciplinary judgment.
Explicit competency requirements for reviewers, aligning domain expertise with decision authority, so that reviewers can meaningfully challenge AI outputs.
Two risks are often overlooked. Cognitive overload and decision fatigue can degrade human judgment over time. And override behavior itself is a signal: persistent reviewer disagreement or high override rates should trigger investigation, not normalization.
5. Operational Resilience
AI systems will fail. The questions are the impact of those failures and how gracefully operations degrade when they occur. Operational resilience determines how an organization absorbs disruption, recovers, and learns, and it includes:
Tested fallback procedures for when AI systems are unavailable or unreliable. Untested runbooks are assumptions, not controls. Teams must regularly exercise manual processes and alternative systems.
Business continuity planning for degraded performance, recognizing that failures are rarely binary and more often emerge as declining accuracy, increased latency, or narrowing coverage.
Dependency mapping across third-party models, APIs, and data sources, exposing upstream coupling that can amplify failures or create cascading risk.
Supply chain risk management for external providers, including model deprecation, changing terms, vendor instability, and credible exit strategies before dependencies become existential.
A less visible risk is organizational over-reliance. As AI systems embed into operations, teams may lose the ability to operate without them. Resilience planning must account not only for technical failure, but for erosion of human and organizational capability.
The Feedback Loop That Makes Governance Real
Operational risk management comprises both execution and measurement. As shown in the graphic below, operational metrics feed governance decisions through a closed-loop system:
Governance sets risk thresholds and expectations.
Operations measures performance against them (utilizing the five domains).
Deviations, trends, and near-misses trigger escalation.
Governance revises policy, thresholds, or strategy (closing the loop through continuous improvement).
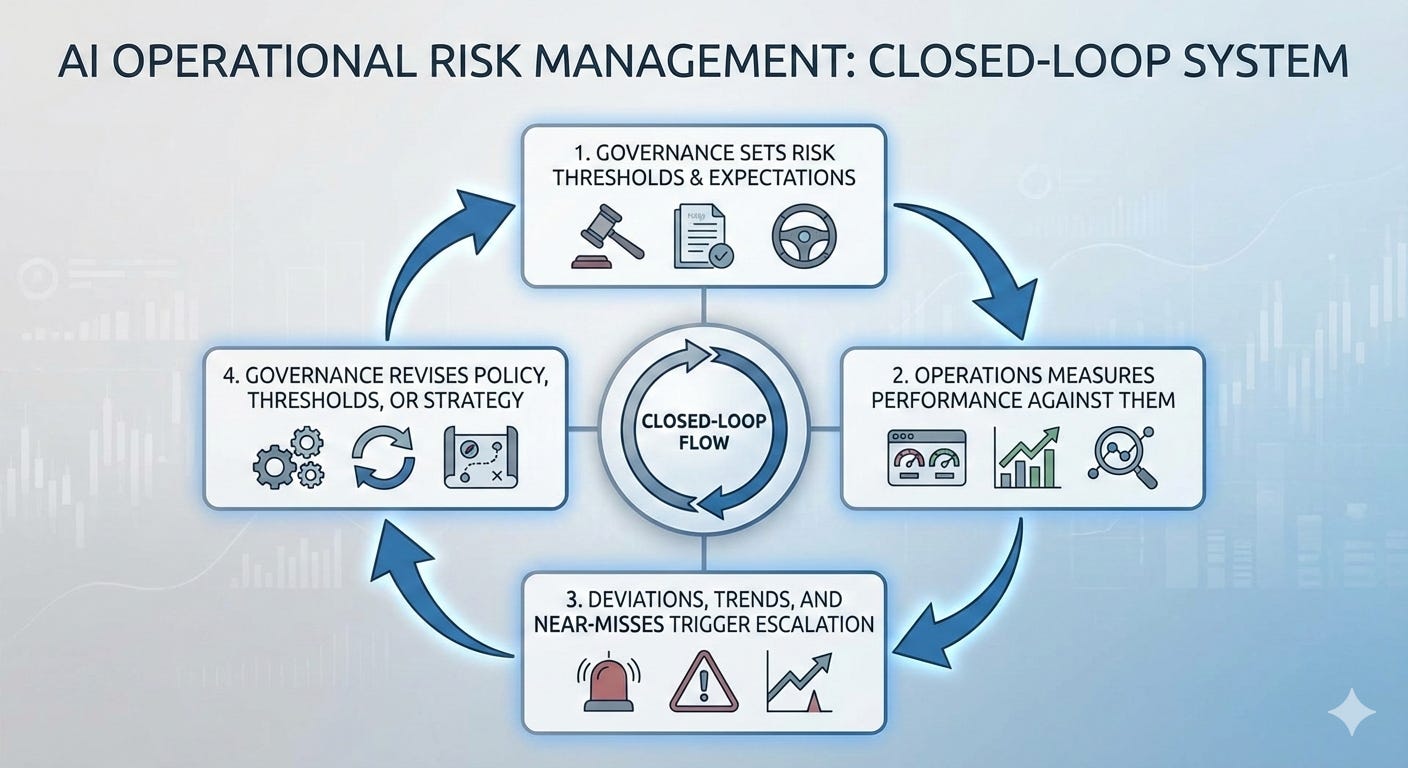
The most common failure is treating governance as a one-way flow. Policies are issued, controls are implemented, and signals from operations are informally noted but rarely elevated. Patterns go unexamined; near-misses are ignored; drift becomes normal; and failures which should have been predictable come without warning.
Without operational measurement, governance cannot learn. Without governance direction, operations cannot prioritize. Establishing these feedback loops may require modest upfront effort, but it consistently pays dividends over time.
A Question for Leaders
Every leader reading this should ask a simple question: When operational AI metrics indicate rising risk, who is required to act, and at what level? If the answer depends on discretion rather than design, the gap is not simply operational. It’s a defensibility gap, especially when auditors or regulators ask for evidence of ownership and escalation. As AI-specific expectations and requirements emerge across jurisdictions and industries, the absence of clear ownership, escalation, and evidence of learning will be harder to defend after an incident than the incident itself.
The practical next step is simple: select one high-impact AI system within your organization and trace how risk signals surface, escalate, and trigger executive action. If that path is unclear, governance exists on paper, not in operations. AI governance is not about slowing adoption; it is about making adoption durable, and durability is earned through accountability, escalation, and learning that operate continuously at scale.
 | A guest post by
|